A Practical Deep Dive into AWS Trainium & Inferentia2 for High-Performance, Cost-Efficient AI

AWS continues to push the boundaries of AI infrastructure with two purpose-built accelerators: AWS Trainium (for training) and AWS Inferentia2 (for inference).
For engineers building GenAI systems — especially on Kubernetes, serverless, or distributed architectures — understanding these chips and the AWS Neuron SDK is becoming essential.
This post distills the core concepts, architecture insights, and practical guidance from the official AWS documentation into a single, actionable guide.
Why Trainium & Inferentia2 Matter
Cloud-scale AI is bottlenecked not only by GPU availability, but also by cost efficiency and energy consumption. AWS designed Trainium and Inferentia2 to solve these exact gaps:
Significant cost reductions compared to traditional GPU-based workloads
Reduced power draw per token generated or trained
Optimized for the models most teams actually run (transformers, LLMs, diffusion models)
Tightly integrated with PyTorch, TensorFlow, Hugging Face, DeepSpeed, and JAX
Production-first tooling via Neuron SDK
These chips aren’t competitors to GPUs — they’re complements. For many workloads, they offer a better price–performance curve with minimal code changes.
1. AWS Trainium — Purpose-Built for Deep Learning Training
Trainium is optimized for:
LLM training
Diffusion model training
Transformer-based architectures
Distributed data, model, and pipeline parallelism
Key Architecture Concepts
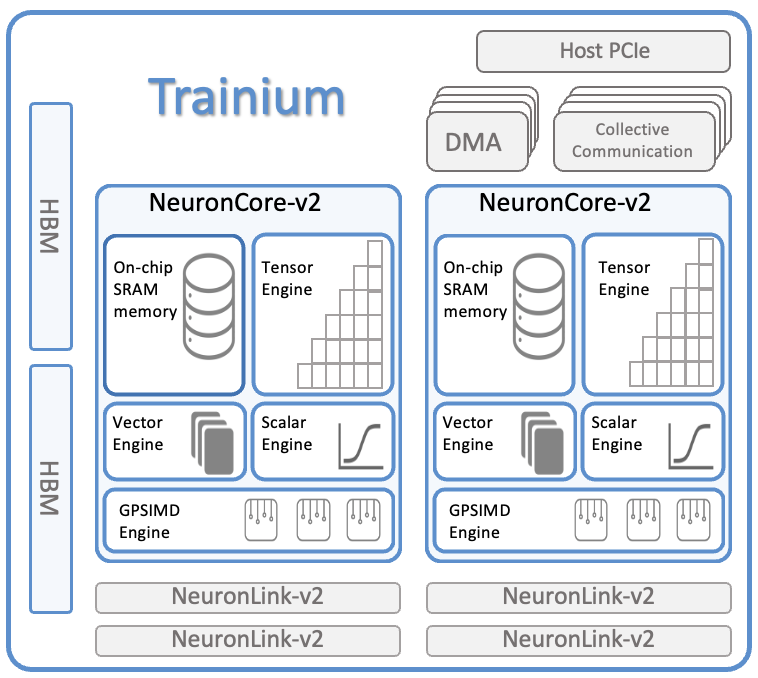
NeuronCores
Trainium chips contain multiple NeuronCores — the execution units for matrix ops, attention, and training-specific routines (like mixed precision).
High-Speed Interconnect (Neuronic Fabric)
Enables synchronized training across multiple accelerators
Low latency collective ops (critical for LLM training)
Efficient model parallel + data parallel hybrid setups
BF16 + FP8 Training Support
This is where the efficiency gains become obvious:
Reduced memory footprint
Faster throughput
Minimal accuracy regression
Elastic Fabric Adapter (EFA)
When scaling horizontally, Trainium clusters leverage EFA for low-latency collective communication — crucial for 10B+ model training.
2. AWS Inferentia2 — Cost-Optimized High-Throughput Inference
📄 Docs: AWS Inferentia2 Overview
Inferentia2 is built for production inference workloads:
LLM inference (GPT, LLaMA, Falcon, Mistral, Qwen, etc.)
Diffusion model generation
RAG pipelines
High-throughput, low-latency serving
Why Inferentia2 is compelling
Up to 4× throughput of first-gen Inferentia
40% lower energy consumption than GPU equivalents
Huge performance jumps for attention-heavy workloads
Native support for FP8 and BF16
Ideal for Kubernetes-based autoscaling (EKS + Neuron)
Architecture Highlights
📄 Inferentia2 Architecture Guide
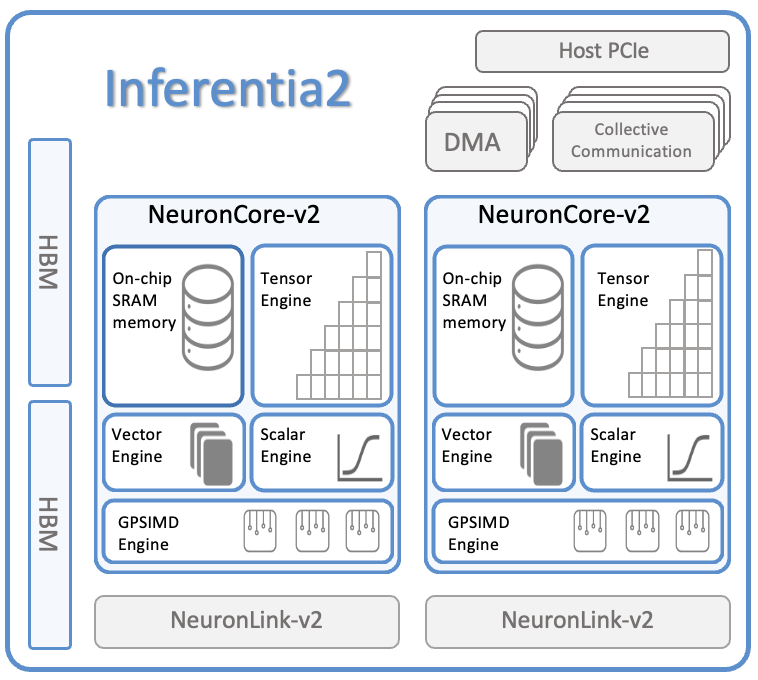
Multiple NeuronCores-v2 per accelerator
Dedicated tensor engines for parallel matmul
Hardware-accelerated transformer engine
Optimized KV cache management for LLMs
Designed for horizontal scale in inference clusters
3. AWS Neuron SDK — The Engine Behind Trainium & Inferentia2
The Neuron SDK includes:
Neuron Compiler (converts PyTorch/TensorFlow graphs to Neuron-optimized IR)
Neuron Runtime (executes compiled graphs on Trn/Inf chips)
Neuron Monitor (profiling, performance insights)
Neuron DL Frameworks (optimized PyTorch, TF, JAX wheels)
Supported frameworks
PyTorch Neuron
TensorFlow Neuron
JAX Neuron
Hugging Face Optimum Neuron
DeepSpeed for distributed training
Developer Workflow
Training on Trainium
pip install torch-neuronx
neuronx-cc --model model.py --output model-neuron/
Inference on Inferentia2
pip install torch-neuronx
python -m neuronx-distributed.launch server.py
The Neuron toolchain abstracts the hardware.
Your PyTorch code remains largely unchanged — core operations are offloaded automatically.
4. When to Choose Trainium or Inferentia2
Choose Trainium when…
Training LLMs (7B–70B scale)
Fine-tuning on domain datasets
Training diffusion/vision models
Scaling out distributed model parallelism
You need the lowest training cost per token
Choose Inferentia2 when…
Running LLM inference at scale
Serving models inside API services or EKS workloads
Powering RAG pipelines with custom embeddings
Hosting chatbots, agents, or multimodal models
You need predictable latency + low cost
5. Trainium & Inferentia2 in Real Architectures
Here’s where these accelerators shine in real AWS platforms:
EKS + Neuron (Containers)
Trainium nodes for distributed fine-tuning
Inferentia2 nodes for cost-optimized LLM inference
Karpenter automates heterogeneous node provisioning
Node pools tuned for Neuron driver/runtime prewarm
Serverless Inference
Future-ready runtimes will support Neuron-compiled models
Ideal for microservices-based inference
Batch + EMR on EKS
Embedding generation
Diffusion offline batch jobs
Model conversion & Neuron compilation pipelines
6. Code Example — Running LLaMA on Inferentia2
Hugging Face Optimum Neuron makes it straightforward:
from optimum.neuron import NeuronModelForCausalLM, NeuronTokenizer
model = NeuronModelForCausalLM.from_pretrained(
"meta-llama/Llama-3-8B",
export=True,
auto_cast="bf16"
)
tokenizer = NeuronTokenizer.from_pretrained("meta-llama/Llama-3-8B")
inputs = tokenizer("Hello from Inferentia2!", return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(outputs[0]))
This runs directly on Inferentia2 via the Neuron runtime.
Final Thoughts
Trainium and Inferentia2 are no longer niche accelerators — they are rapidly becoming mainstream for teams running GenAI on AWS.
Their value is simple:
Train models cheaper.
Serve models cheaper.
Scale reliably on battle-tested AWS infrastructure.
With the Neuron SDK maturing quickly and ecosystem support growing (Hugging Face, PyTorch, JAX, Karpenter, EKS), adopting these accelerators is becoming smoother by the month.
If you're building next-generation AI platforms, especially container-native ones, Trainium and Inferentia2 deserve to be in your architectural toolkit.




