


Table of contents
- Low latency modern data streaming applications
- Build access logs streaming applications using Kinesis Data Firehose and Kinesis Data Analytics
- Stream data from diverse source systems into the data lake using MSK for near real-time reports
- Build a serverless streaming data pipeline using Amazon Kinesis and AWS Glue
- Set up near real-time search on DynamoDB table using Kinesis Data Streams and OpenSearch Service
Low latency modern data streaming applications
Following are a few use cases for when you need to move data around the purpose-built data services with low latency for faster insights, and how to build these streaming application architectures with AWS streaming technologies.
Build access logs streaming applications using Kinesis Data Firehose and Kinesis Data Analytics
Customers perform log analysis that involves searching, analyzing, and visualizing machine data generated by your IT systems and technology infrastructure. It includes logs and metrics such as user transactions, customer behavior, sensor activity, machine behavior, and security threats. This data is complex, but also the most valuable, as it contains operational intelligence for IT, security, and business.
In this use case, customers have collected log data in an Amazon S3 data lake. They need to access log data and analyze it in a variety of ways, using the right tool for the job for various security and compliance requirements. There are several data consumers including auditors, streaming analytics users, enterprise data warehouse users, and so on. They need to keep a copy of the data for regulatory purposes.
The following diagram illustrates the modern data architecture inside-out data movement with input access logs data, to derive near real-time dashboards and notifications.
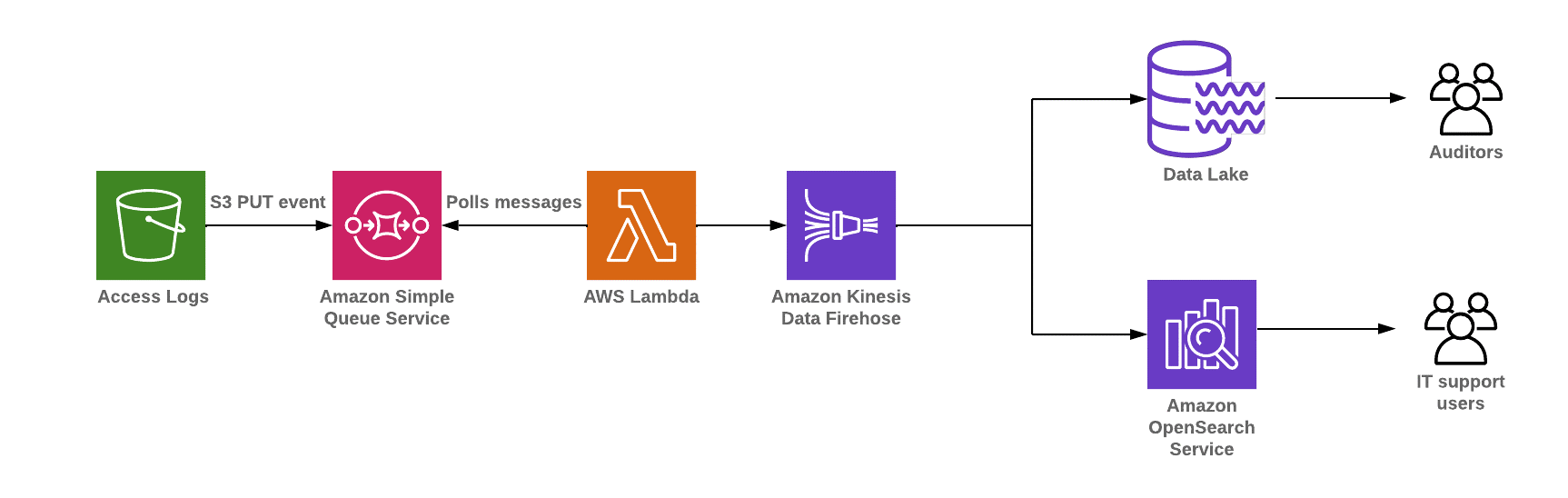
Access logs streaming applications for anomaly detection using Amazon Kinesis Data Analytics and Amazon OpenSearch Service
The steps that data follows through the architecture are as follows:
- Logs from multiple sources such as Amazon CloudFront access logs, VPC Flow Logs, API logs, and application logs are pushed into the data lake.
- Publish S3 PUT events to Amazon SQS events. AWS Lambda polls the events from SQS and invokes a Lambda function to move data into multiple sources such as Amazon S3, Amazon Redshift, Amazon OpenSearch Service, or Kinesis Data Analytics using Amazon Kinesis Data Firehose.
- You can build low latency modern data streaming applications by creating a near real-time OpenSearch dashboard, and then processing streaming analytics out with AWS Lambda and Amazon SNS automatic notifications.
- You can also store access log data into Amazon S3 for archival, and load sub-access log summary data into Amazon Redshift, depending on your use case.
Stream data from diverse source systems into the data lake using MSK for near real-time reports
Customers want to stream near real-time data from diverse source systems such as Software as a Service (SaaS) applications, databases, and social media into S3, and to online analytical processing (OLAP) systems such as Amazon Redshift, to derive user behavior insights and to build better customer experiences. Hopefully these experiences will drive more reactive, intelligent, near real-time experiences. This data in Amazon Redshift can be used to develop customer-centric business reports to improve overall customer experience.
The following diagram illustrates the modern data architecture outside-in data movement, with input stream data to derive near real-time dashboards.
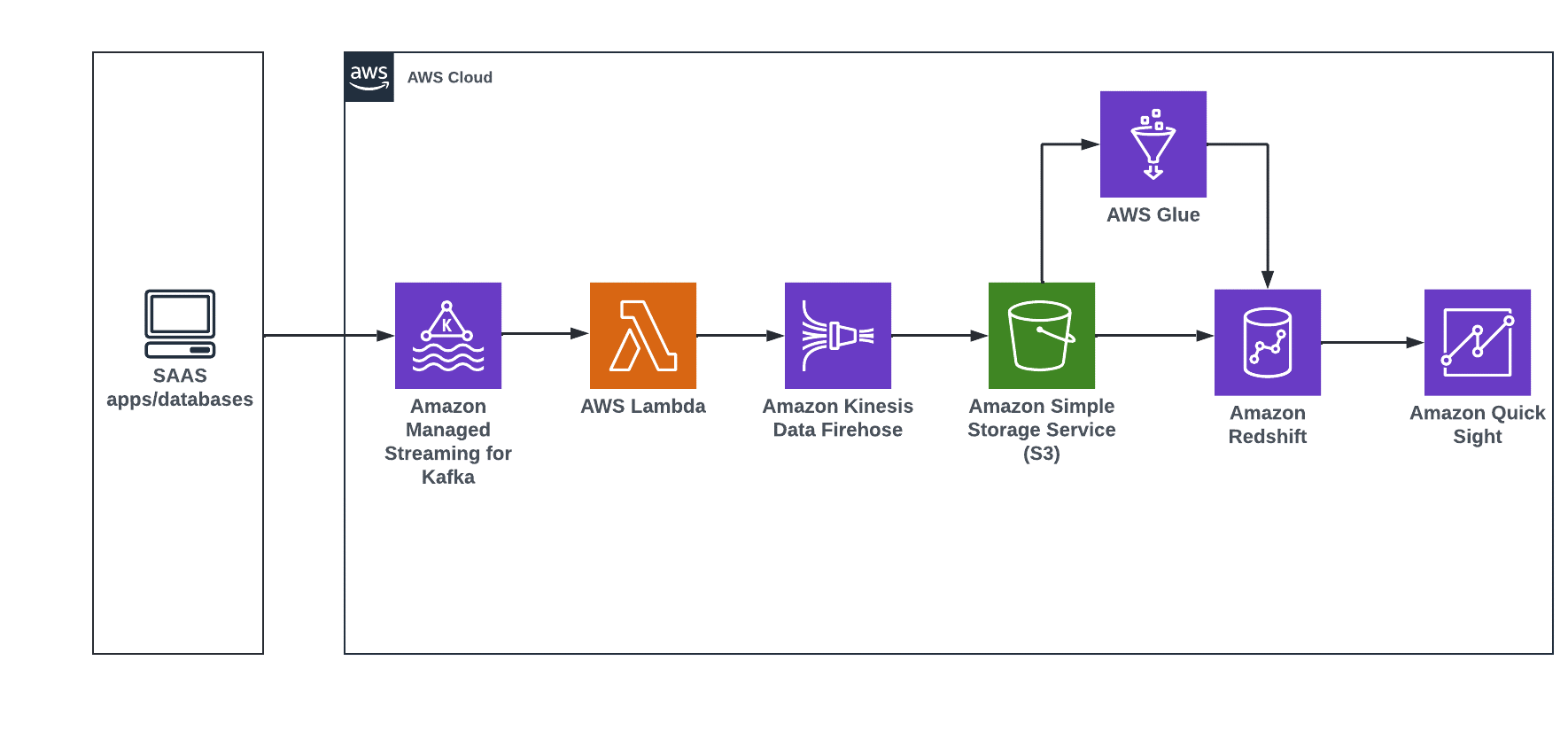
Derive insights from input data coming from diverse source systems for near real-time dashboards with Amazon QuickSight.
The steps that data follows through the architecture are as follows:
- Stream near real-time data from source systems such as social media using Amazon MSK, Lambda, and Kinesis Data Firehose into Amazon S3.
- You can use AWS Glue for data processing, and load transformed data into Amazon Redshift using a Glue development endpoint such as Amazon SageMaker notebook instances.
- Once data is in Amazon Redshift, you can create a customer-centric business report using Amazon QuickSight.
Build a serverless streaming data pipeline using Amazon Kinesis and AWS Glue
Customers want low-latency near real-time analytics to process users’ behavior and respond back almost instantaneously with relevant offers and recommendations. The customer’s attention will be lost if these recommendations are not available for days, hours, or even minutes – they need to happen in near real-time. The following diagram illustrates a typical modern data architecture for a streaming data pipeline to keep the application up to date, and to store streaming data into a data lake for offline analysis.
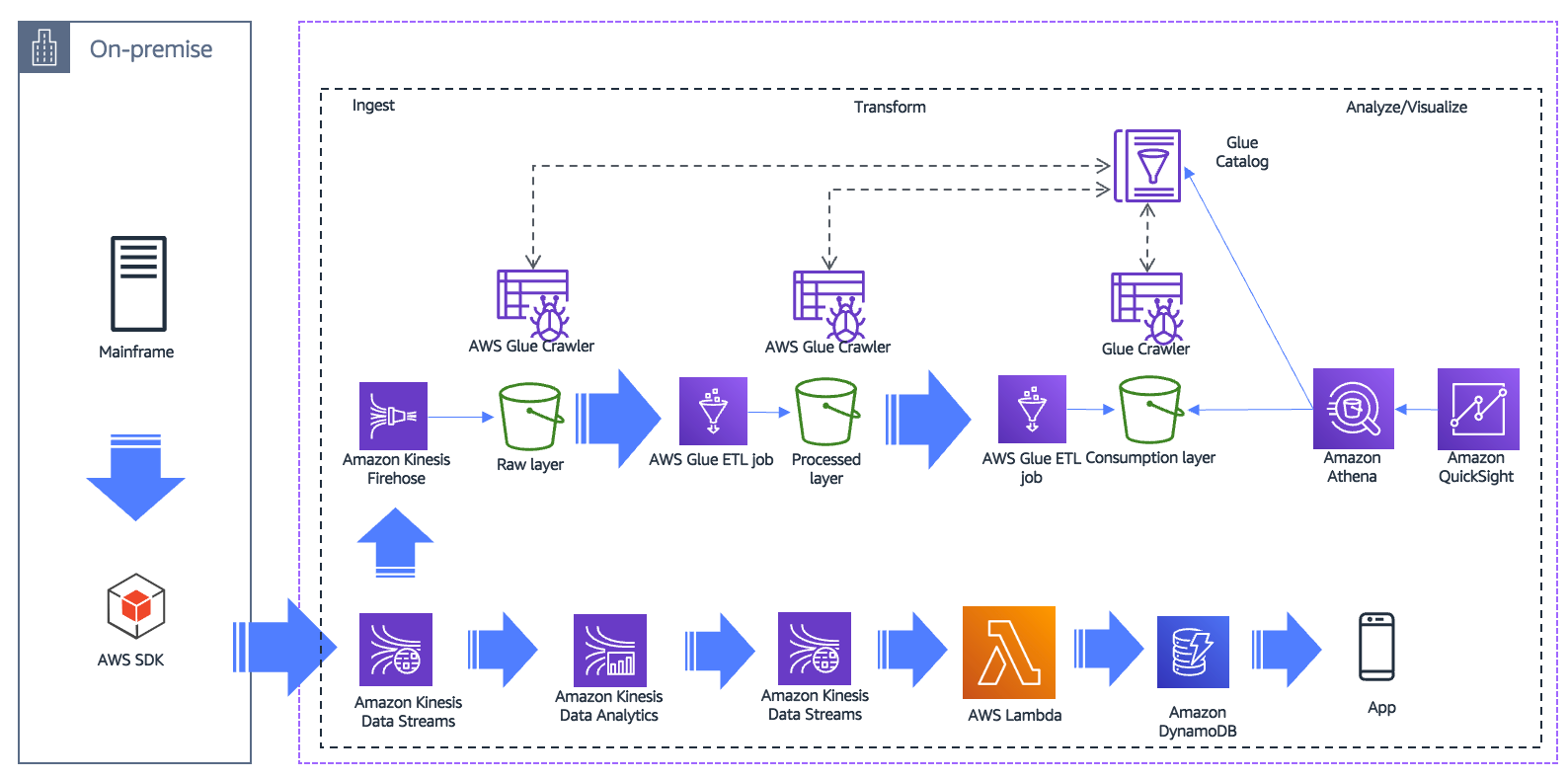
Build a serverless streaming data pipeline
The steps that data follows through the architecture are as follows:
- Extract data in near real-time from an on-premises legacy system to a streaming platform such as Apache Kafka. From Kafka, you can move the data to Kinesis Data Streams.
- Use Kinesis Data Analytics to analyze streaming data, gain actionable insights, and respond to your business and customer needs in near real-time.
- Store analyzed data in cloud scale databases such as Amazon DynamoDB, and push to your end users in near real-time.
- Kinesis Data Streams can use Kinesis Data Firehose to send the same streaming content to the data lake for non-real-time analytics use cases.
Set up near real-time search on DynamoDB table using Kinesis Data Streams and OpenSearch Service
Organizations want to build a search service for their customers to find the right product, service, document, or answer to their problem as quickly as possible. Their searches will be across both semi-structured and unstructured data, and across different facets and attributes. Search results have to be relevant and delivered in near real-time. For example, if you have an ecommerce platform, you want customers to find the product they are looking for quickly in near real-time.
You can use both DynamoDB and OpenSearch Service for building a near real-time search service. You can use DynamoDB as a durable store, and OpenSearch Service to extend its search capabilities. When you set up your DynamoDB tables and streams to replicate your data into OpenSearch Service, you can perform near real-time, full-text search on your data. You can also load part of the data into Amazon Redshift, depending on your use case.
The following diagram illustrates the modern data architecture around the perimeter data movement with Amazon DynamoDB and Amazon OpenSearch Service.
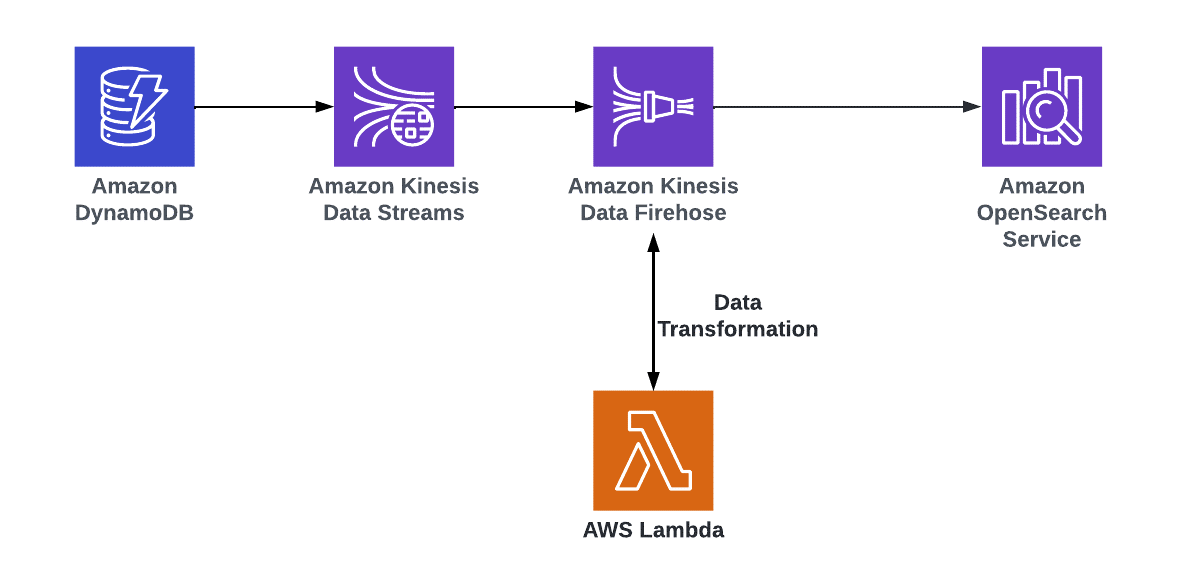
Derive insights from Amazon DynamoDB data by setting up near real-time search using Amazon OpenSearch Service
The steps that data follows through the architecture are as follows:
- In this design, the DynamoDB table is used as the primary data store. An Amazon OpenSearch Service cluster is used to serve all types of searches by indexing the table.
- Using DynamoDB streams with Kinesis Data Streams, any update, deletion, or new item on the main table is captured and processed using AWS Lambda. Lambda makes appropriate calls to OpenSearch Service for indexing the data in near real-time.
- For more details about this architecture, refer to Indexing Amazon DynamoDB Content with Amazon OpenSearch Service Using AWS Lambda and Loading Streaming Data into Amazon OpenSearch Service from Amazon DynamoDB.
- You can also use streaming functionality to send the changes to OpenSearch Service or Amazon Redshift via a Data Firehose delivery stream. Before you load data into OpenSearch Service or Amazon Redshift, you might need to perform transforms on the data. You can use Lambda functions to perform this task. For more information, refer to Amazon Kinesis Data Firehose Data Transformation.
Hope this guide helps you understand Low latency modern data streaming applications along with a few use cases.
[IMPORTANT]
- This material is not mine. This material was written exclusively by Amazon Web Services.
I am sharing this with a bigger IT audience to help folks in their quest to learn AWS. I don't intend to monetize anything, therefore everything I share will always be free. I'm not interested in profiting off the knowledge of others.
Sharing relevant and helpful content is something I've always thought is a great approach to support the tech community. I'll keep offering my viewers insightful content. Thank you for supporting.